Generative Artificial Intelligence

A young aspiring Data Scientist, who love to build AI and ML applications, that can contribute as a solution in real world problems. I started my coding journey in grade 8, since then I have developed solutions to many organizations.
Artificial Intelligence (AI) has been one of the most revolutionary advancements in the field of technology in recent years. The ability of machines to perform complex tasks previously only possible for humans has transformed the way we live, work, and interact with each other. One of the latest and most exciting advancements in the field of AI is Generative AI. This technology allows machines to create new and unique content such as images, videos, and even entire stories without human intervention. In this blog post, we will explore the maths behind Generative AI. The images in this blog are taken from 'youtube'.
What is this?
Generative AI is a rapidly evolving field of Artificial Intelligence that is focused on developing algorithms capable of generating new content autonomously. This is achieved through the use of generative models that are trained on a dataset of existing content. The models then use this data to generate new examples that are similar in style, structure, and content to the original dataset.
There are various types of generative models used in AI, such as the Naive Bayes Classifier, Gaussian Mixture Model, and Generative Adversarial Networks (GANs). These models are designed to create new examples that mimic the features of the training data by learning patterns, relationships, and distributions within the dataset.
GANs
GAN stands for Generative Adversarial Networks. It is Deep learning-based generative models are used for unsupervised learning. Two neural networks compete with each other to generate variations in the data.
This concept was first published in "Alec Radford Paper in the year 2016 - DCGAN (Deep Convolutional General Adversarial Networks)".
It uses two sub-models
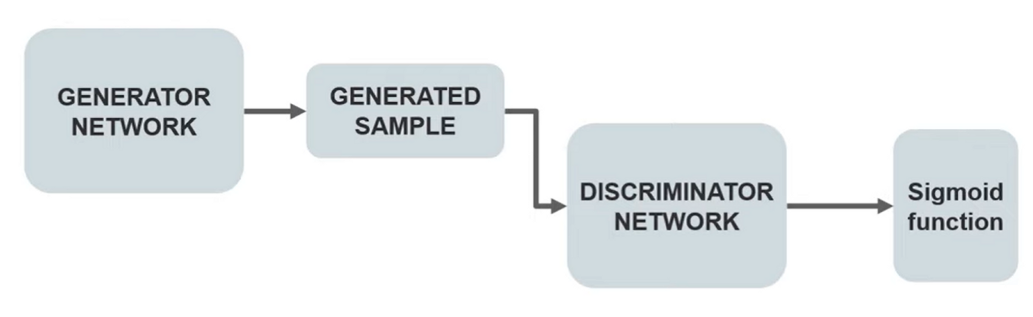
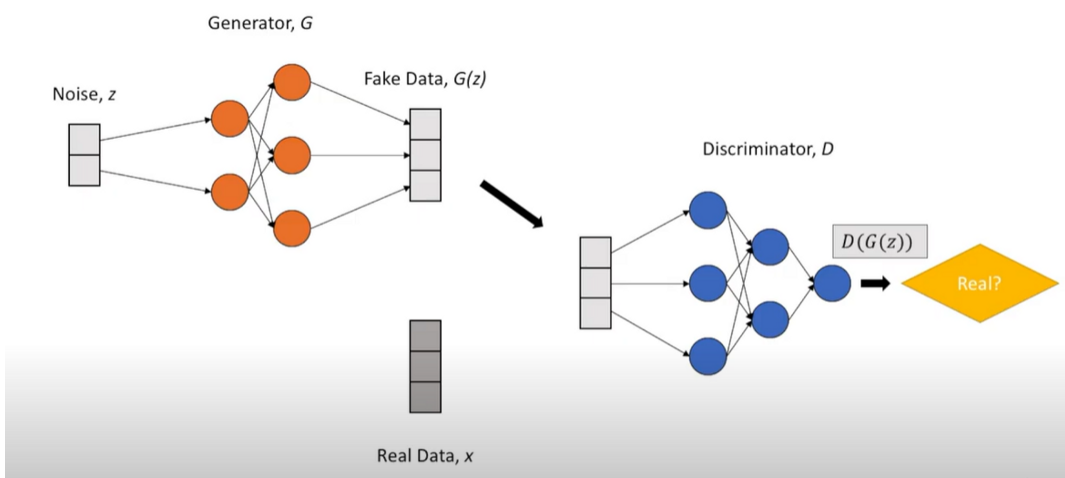
Generator: The generator network takes a sample and generates a sample of data. Used to generate fake data for negative sampling.
Discriminator: Discriminator network decides whether the data is generated or taken from the real sample using binary classification using the sigmoid function giving output 0 or 1.
How does GAN work
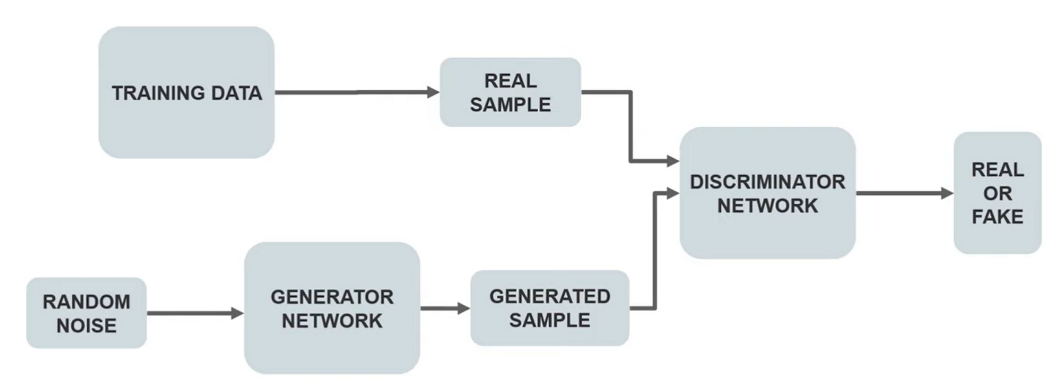
First, the GAN model is trained on a dataset of real samples. This dataset serves as a reference for the generator network to generate new samples that resemble the real data.
During the training process, the generator network takes random noise as input and generates a sample. This generated sample is then passed on to the discriminator network.
The discriminator network is designed to differentiate between real and fake samples. It takes both the real and generated samples as input and provides an output that indicates whether the sample is real or fake.
The generator network then adjusts its parameters based on the feedback from the discriminator network. If the generated sample is classified as fake, the generator network modifies its parameters to generate a sample that is more similar to the real data. This process continues until the generator network can generate samples that are indistinguishable from the real data.
The discriminator network is also simultaneously updated during the training process. Its goal is to accurately distinguish between real and fake samples. The updates to the discriminator network are based on the accuracy of its classification of the generated samples.
This process of training and updating both the generator and discriminator networks continues until the generator network can generate samples that are virtually indistinguishable from the real data.
Training a GAN Model
Train the discriminator and freeze the generator, which means the training set for the generator is turned as False and the network will only do the forward pass and no back-propagation will be applied.
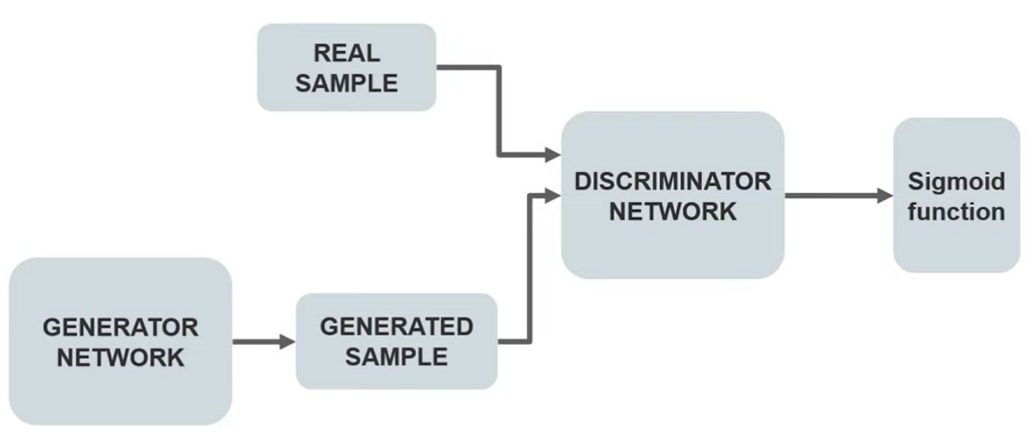
Train the generator and freeze the discriminator. In this phase, we get the results from the first phase and can use them to make better from the previous state to try and fool the discriminator better.
Mathematical Formulation of GAN
$$\min_G \max_D V(D,G) = \mathbb{E}_{x \sim p_{\text{data}}(x)}[\log D(x)] + \mathbb{E}_{z \sim p_z(z)}[\log(1 - D(G(z)))]$$
The function is the objective function of a generative adversarial network (GAN) and is used to train the generator and discriminator networks in the GAN.
The objective of the GAN is to generate synthetic data that closely resembles the real data. The function represents a minimax game between the generator network (G) and the discriminator network (D), where G tries to minimize the function and D tries to maximize it.
The function takes as input two probability distributions: the distribution of the real data samples (p_data(x)) and the distribution of the noise vector (p_z(z)). It has two terms, each representing an expected value.
The first term represents the expected value of the logarithm of the discriminator's output when fed real data samples. The discriminator network tries to maximize this term by correctly classifying real data samples as real.
The second term represents the expected value of the logarithm of 1 minus the discriminator's output when fed generated samples from the generator network. The generator network tries to minimize this term by generating samples that the discriminator network classifies as real.
By minimizing this function, the generator network learns to generate synthetic data that is similar to the real data, while the discriminator network learns to distinguish between real and fake samples. The training process continues until the generator network can generate synthetic data that is indistinguishable from the real data.
For Fake Data
For Real Data
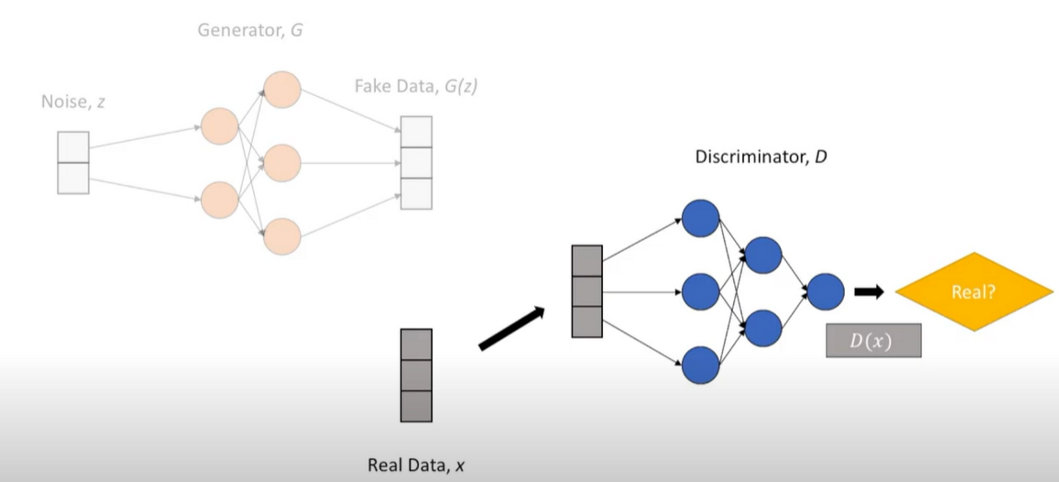
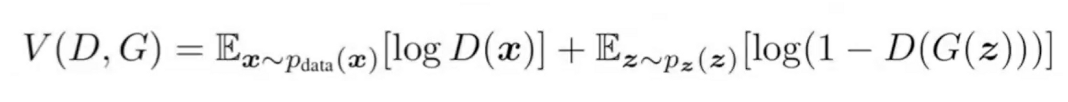
Here the unsupervised model (non-labelled data, real and fake) is being converted to a supervised model through Adversarial Framework
E(x~p_data(x))[log D(x)] - Discriminative prediction on real data. The expectation of log when the input is from the real data distribution. Basically, the average of the discriminator's predictions when data is real. Discriminator wants a high D(x) value
E(z~p_data(z))[log D(G(x))] - Discriminative prediction on fake data. The expectation of the log is when we pull a lot of input noise from the generator. Discriminator wants a low D(G(z)) value showing the confidence
Types of GAN
There are several types of generative adversarial networks (GANs) that have been developed, each with its own unique architecture and training procedure. Here are some of the most common types of GANs:
Vanilla GANs: These are the standard GANs that were introduced by Ian Goodfellow in 2014. They consist of a generator network that generates fake samples and a discriminator network that distinguishes between real and fake samples.
Conditional GANs: These are GANs that are conditioned on additional information, such as class labels or images. The additional information is typically fed into both the generator and discriminator networks to help them generate and distinguish between samples that belong to different categories.
Deep Convolutional GANs (DCGANs): These are GANs that use deep convolutional neural networks (CNNs) as both the generator and discriminator networks. They are particularly effective for generating high-resolution images.
Wasserstein GANs (WGANs): These are GANs that use a different loss function based on the Wasserstein distance between the real and fake data distributions. This loss function is more stable than the one used in vanilla GANs and can lead to better results.
CycleGANs: These are GANs that learn to translate between two different domains, such as turning a photo into a painting. They consist of two GANs, one for each domain, that are trained in an adversarial manner to generate samples that can be translated between the two domains.
Progressive GANs: These are GANs that generate high-resolution images by gradually increasing the resolution of the generated images during training. They are able to generate images that are much higher in resolution than other types of GANs.
These are just some of the many types of GANs that have been developed. Each type has its own advantages and disadvantages, and the choice of which type to use depends on the specific application and the desired outcome.
Conclusion
To sum up, generative AI has the potential to revolutionize many fields by enabling machines to create new data and generate novel solutions to complex problems. The development of generative models such as GANs, VAEs, and autoregressive models has opened up new avenues for creativity, innovation, and problem-solving. From generating art, music, and literature to synthesizing new materials, drugs, and molecules, generative AI is unlocking new possibilities in many domains. While there are still many challenges to be overcome, such as improving the stability and diversity of generated samples, the future of generative AI looks bright, and we can expect to see many exciting advances in this field in the years to come.
That's all for this blog, For any queries, feel free to write in the comments or reach out to me over different social media platforms. Know more at https://www.lakshaykumar.tech/